
Im Rahmen der 'doppelten Gliederung' natürlicher Sprachen (Martinet) haben wir uns über die Phoneme (= kleinste bedeutungsunterscheidende Einheiten) hinaus mit Morphemen (kleinste bedeutungstragende Einheiten) beschäftigt; und hier haben wir zwischen lexikalischen Morphemen (in der Literatur häufig auch "Lexem" genannt) und grammatischen Morphemen beschäftigt (in der Literatur wird der "Morphem-Begriff" von Fall zu Fall auch auf die grammatischen Morpheme eingeschränkt).
Morpheme sind kleinste bedeutungstragende Einheiten, so hatten wir gesagt. Heißt das, dass eine umfangreichere Äußerung bzw. deren Bedeutung gewissermaßen die Summe der Teilbedeutungen der verwendeten (geäußerten) Morpheme ist? Etwa nach der Formel
A (Morphem a) + B (Morphem b) + ... ... = X (Bedeutung der Gesamtäußerung x)Nun gilt aber, dass "A + B = B + A"; also müßte u.a. gelten
"hundert - zwei = zwei - hundert"Offensichtlich stimmt das nicht; offensichtlich spielt auch die Abfolge der einzelnen Morpheme und Morphemgruppen eine wichtige Rolle. Im Falle der Zahlwörter gilt offenbar: wenn das kleinere Zahlwort (z. B. "zwei") vor dem größeren Zahlwort steht (z. B. "hundert"), dann bedeutet das Multiplikation (200 = 2 x 100). Steht das größere Zahlwort vor dem kleineren Zahlwort, dann bedeutet das Addition (102 = 100 + 2). Dabei kann natürlich auch beides miteinander verbunden werden, - vgl. "zwei-hundert-zwei" (202 = [2 x 100] + 2).
Die Reihenfolge drückt eine jeweilige Ordnung aus, in der die Segmente auttreten; eine (im übrigen syntagmatische - siehe dazu schon weiter oben) Ordnung, die ihrerseits zur Gesamtbedeutung einer komplexen Äußerung beiträgt. Dabei sind Reihenfolgen nicht die einzige Möglichkeit, die syntagmatische Ordnung zu kennzeichnen, die einer Reihe von Morphemen und Morphemgruppen zugrundeliegt; beispielsweise kann ich das in der gesprochenen Sprache auch mithilfe der Tonhöhenabfolge oder -kontur:
In beiden Fällen handelt es sich um Äußerungen, die als Fragesätze bezeichnet werden. - Wir werden gleich unten auf weitere Möglichkeiten zu sprechen kommen, eine je spezifische syntagmatische Ordnung von Morphemen zu kennzeichnen. Hier wollen wir im Moment nur festhalten, eben: dass wir in kompleren Äußerungen die geäußerten Morpheme immer in einer spezifischen syntagmatischen Ordnung äußern. - Solche Ordnungen oder Ordnungsmuster haben in der Sprachwissenschaft einen Namen (z.B. Fragesatz oder Aussagesatz); wichtiger noch gilt, dass wir solche syntagmatischen Ordnungen und Ordnungsmuster nicht ad hoc erfinden, sondern dass wir hier einem vorgegebenen Inventar folgen, dass für eine Sprache (manchmal auch für ganze Gruppen von Sprachen) spezifisch ist.
Es gibt in der Sprachwissenschaft eine bestimmte Teildisziplin, die die oben angesprochenen syntagmatischen Ordnungen und Ordnungsmuster zum Gegenstand macht, die Syntax. Zur Syntax gehören u.a. eine Vielzahl von Testverfahren (von denen wir einige ansatzweise schon kennengelernt haben - mehr dazu gleich unten), und das ganz einfach deshalb, weil man häufig die einer Äußerung zugrundeliegende Ordnung nicht 'sehen' kann; man muß sie mithilfe von Testverfahren austesten.
6.2. Syntax und MorphosyntaxZu den Ausdrucksmitteln und Verfahren, mithilfe deren wir deutlich machen, in welcher Ordnung Morpheme und Morphemgruppen geäußert werden, gehören auch eine Reihe grammatischer Morpheme. Man vergleiche die folgende Äußerung, die doppeldeutig ist, weil wir zwei unterschiedliche Ordnungsmuster beim Verstehen zugrundlegen können:
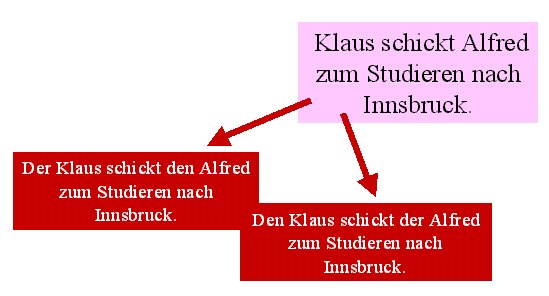
Wir haben es hier mit gleichen Reihenfolgen zu tun; gesprochen-sprachlich unterstelle ich gleiche Tonhöhenkonturen. Mit anderen Worten geht der Unterschied der Gesamtbedeutung zu Lasten der Zuordnung von Kasusmarkierungen: Wird "Klaus" mit dem Nominativ markiert, dann ist er es, der jemanden schickt, wird "Klaus" hingegen mit dem Akkusativ markiert, dann ist er es, der geschickt wird (und das macht ja nun einen gewaltigen Unterschied).
Greifen wird auf die eingeschränkte Rede von den grammatischen Morphemen als Morphemen und den lexikalischen Morphemen als den Lexemen zurück, dann kann man von syntaktisch relevanten (grammatischen) Morphemen sprechen, von einem Ausschnitt der Morphologie, den wir deshalb auch "Morphosyntax" nennen (und zur Morphosyntax gehören - das haben wir gerade gelernt - u.a. die Kasusmorpheme).
6.3. Morpheme und WörterBisher haben wir stets von (lexikalischen und grammatischen) Morphemen gesprochen. Wir sehen aber, dass schriftsprachlich (ganz anders und dennoch im Prinzip vergleichbar lautsprachlich) häufig ein lexikalisches und ein oder mehrere grammatische Morpheme zusammengeschrieben und vorweg wie hinterher durch einen Freiraum von anderen Morphemen abgegrenzt werden. Wir sprechen dann auch von Wörtern, und der Unterschied zwischen einem einzelnen Morphem und einem solchen Wort kann recht drastisch sein, - vgl. (ich) lachte = lach-t-e:

Dass es sich hier in der Tat um ein Wort handelt, dass aus drei Morphemen - aus einem lexikalischen Morphem (dem Stamm) und zwei grammatischen Morphemen - besteht, haben wir schon weiter oben im Rahmen der Morphologie besprochen und haben dort auch erläutert, dass die paradigmatischen Austauschverhältnisse (Substitutionstest - siehe oben, dazu auch gleich noch unten) beim Mittelsegment wie beim Endsegment belegen, dass ich zu Recht jeweils ein eigenes Morphem angesetzt habe. - Gegebenenfalls kann ich schriftsprachlich sogar mehrere lexikalischen Morpheme plus grammatische Morpheme zu einem Wort zusammenfügen, - man vergleich solche Wortungetüme wie
Kind-er-garten-spiel-zeug-e Es gibt verschiedene Versuche einer Definition von "Wort", unabhängig seiner graphischen Realisierung (das meint, dass ein schriftsprachliches Wort jeweils vorweg und im Anschluß durch einen Freiraum von anderen Wörtern getrennt ist). Am interessantesten sind Überlegungen, die bei gleicher Bedeutung und gleicher Wortart ("lache" oder "lachst" oder "lachtest" sind alles Verben, deren lexikalische Bedeutung identisch ist) von ein- und demselben Wort sprechen. Doch stoßen solche Überlegungen schnell an Grenzen, denn wie sieht das bei gesprochen-sprachlichen Wörtern aus, die zunächst ebenfalls nur durch Pausen von anderen Wörtern getrennt sind? Gerade in Sprachen wie dem Französischen, aber auch im Deutschen, gilt darüberhinaus, dass solche gesprochen-sprachlichen Wörter bzw. die entsprechenden Pausen abhängig vom Sprechtempo und anderen Einflußfaktoren an je verschiedenen Stellen auftreten.Innerhalb von Wörtern sind im Deutschen die grammatischen Morpheme grundsätzlich nicht betont (es sei denn, ich betone 'metasprachlich', etwa um die Aussprache oder eine Schreibweise zu korrigieren - dann geht es aber nicht mehr darum, etwas über die Welt auszusagen, sondern dann beziehe ich mich auf die Sprache und sprachliche Ausdrücke; wir sprechen hier auch von 'Metasprache' bzw. eben von 'metasprachlicher Betonung'). So gesehen läßt sich auch argumentieren, dass sich die grammatischen Morpheme einem lexikalischen Morphem (oder auch einer Kette lexikalischer Morpheme) anschließen, um ein Wort zu bilden. Das wird besonders augenfällig bei Wörtern, die je nur ein lexikalisches Morphem enthalten, - wir betonen in der fortlaufenden Rede
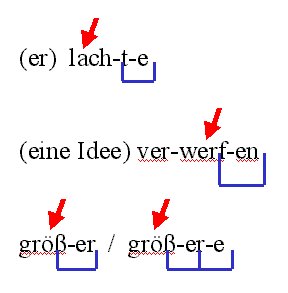
Die einzelnen Morpheme sind oben jeweils durch Gedankenstrich voneinander getrennt. - Wenn die Morpheme nicht mit Silben übereinstimmen, sind die silbischen Segmente der gesprochen-sprachlichen Realisierung zusätzlich durch blaue Striche darunter kenntlich gemacht. - Man sieht sofort, dass jeweils nur die lexikalischen Morpheme betont (markiert mit einem roten Pfeil) werden.
6.4. Syntaktische Testverfahren6.4.1. Der Substitutionstest und seine Anwendung in der Syntax
Schauen wir uns die folgenden Sätze an, dann könnte man auf den Gedanken kommen, als zentrales Kriterium für den Aussagesatz anzunehmen, dass hier das konjugierte Verb stets an zweiter Stelle steht::

Doch gibt es zuhauf auch Aussagesätze, bei denen - geht man von schriftsprachlichen Wörtern aus und zählt diese gemäß ihrem Erscheinen durch - das konjugierte oder finite Verb keineswegs auf dem zweiten Platz steht:

Hier tritt das konjugierte bzw. finite Verb einmal auf dem dritten Platz, einmal auf dem vierten Platz und einmal auf dem siebten Platz auf. Dennoch ist die Rede vom zweiten Platz nicht falsch, nur dass sie nicht auf die 'sprachliche Oberfläche' bezogen werden darf. Wir wissen aus der Anwendung des SUBSTITUTIONSTESTS, daß sich alles, was in einem Aussagesatz vor dem konjugierten Verb oder Verbteil steht, paradigmatisch durch ein einziges Wort ersetzen läßt:

Mit einem Bild: Gezählt werden dürfen eben nicht die Wörter (und schon gar nicht die einzelnen, elementaren Morpheme), sondern so etwas wie Positionen oder Plätze, auf denen aber wesentlich mehr als jeweils nur ein einziges Wort plaziert werden kann. Und der Substitutionstest und seine obige Anwendung belegen, dass es sich bei allem, was im Rahmen eines Aussagesatzes vor dem konjugierten Verb oder Verbteil auftritt, um eine einzige Position handelt.
Es lassen sich leicht noch weitere Positionen bestimmen: So kann ich das konjugierte Verb stets auch an die Spitze auf den ersten Platz vor das Subjekt stellen, nur dass dann in der Regel kein Aussagesatz mehr vorliegt, sondern ein Fragesatz. Doch wird für solche Tests generell nicht verlangt, dass die Bedeutung und der Satztyp des Ausgangsbeispiels erhalten bleiben, sondern es wird lediglich gefordert, dass wieder eine grammatisch korrekte und vollständige Konstruktion entsteht. Und ob das der Fall ist, können wir letztlich nur durch Befragung von Muttersprachlern bzw. 'native speakern' bestimmen.
Besonders wichtig ist die folgende Anwendung des Substitutionstests (wobei es jetzt wieder um Aussagesätze geht): Stets kann ich alles, was nicht zum Subjekt eines Aussagesatzes gehört, ebenfalls durch ein einziges Wort ersetzen. - Der folgende Überblick listet noch einmal einige Subjekte aus den obigen Beispielsätze auf und zeigt, dass jeweils alles andere zusammen paradigmatisch ersetzbar ist - eben: durch ein einziges Wort (und zwar jeweils durch ein Verb):

Mit dem Substitutionstest hängt eng der PRONOMINALISIERUNGSTEST zusammen; er stellt gewissermaßen einen speziellen Ausschnitt aus dem Substitutionstest dar. Immer wenn eine Morphem- und Wortfolge durch ein Pronomen ersetzbar ist, belegt das, dass die Ausgangsfolge eine einzige syntaktische Position realisiert.
In den hier diskutierten Zusammenhang gehört auch der FRAGETEST. Auch er stellt gewissermaßen einen speziellen Ausschnitt aus dem Substitutionstest dar und funktioniert wie der Pronominalisierungstest: Immer wenn ich eine Morphem- und Wortfolge (ganz gleich welcher Komplexität) mit Hilfe eines Fragepronomens erfragen kann, belegt das, dass die Ausgangsfolge eine einzige syntaktische Position realisiert ("Die Nichte des Nachbarn von nebenan fährt morgen nach Paris" - "Wer fährt morgen nach Paris?" - "Die Nichte des Nachbarn von nebenan!").
6.4.2. Der Permutationstest (und der Deletionstest)
Von ganz anderem Zuschnitt ist der sogenannte PERMUTATIONSTEST. Hier versuchen wir, auf welche Weise sich die Wörter und Wortfolgen einer Ausgangsäußerung syntagmatisch umstellen lassen (Achtung: syntagmatisch umstellen, nicht aber paradigmatisch ersetzen). Dabei darf sich erneut die Bedeutung und der Satztyp usw. ändern, es muß sich aber stets eine grammatisch korrekte und vollständige Äußerung ergeben. - In der folgenden Dokumentation sind Morphem- und Wortfolgen, die ungrammatisch und/oder unvollständig sind, durch einen davor gestellten Stern gekennzeichnet und rot geschrieben:

Ein letzter Test - der DELETIONSTEST (oder auch Weglaßprobe), der so etwas wie den Kern einer Äußerung ergibt. Wir testen aus, was alles weggelassen werden kann; allerdings muß sich auch hier als Ergebnis eine grammatisch korrekte und vor allem eine vollständige Äußerung ergeben (vgl. den Beispielsatz oben):
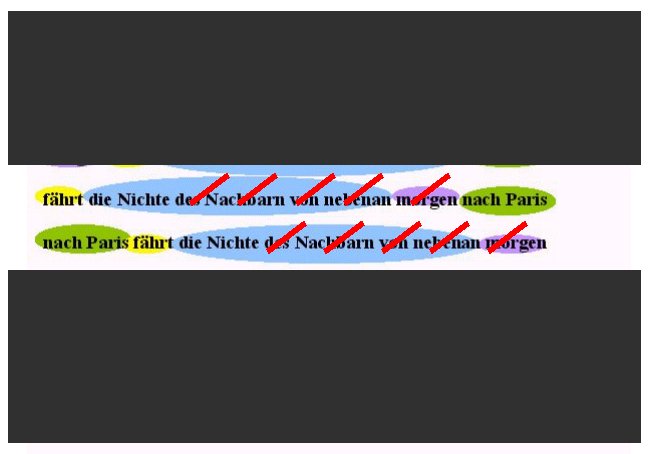
Beide Kernsätze sind vollständig und grammatisch korrekt (gegebenenfalls muß man sich für die Äußerung eines solchen Satzes einen geeigneten Kontext dazudenken). In dieser verkürzten Form wird im übrigen sehr viel deutlicher, wie der Satz aufgebaut ist.
6.5. Die IC-Analyse6.5.1. Die Zerlegung einer Äußerung in konstitutive Gruppen (= unmittelbare Konstituenten)
Gehen wir die obigen Tests noch einmal durch, so zerfällt eine Äußerung wie "Die Nichte des Nachbarn von nebenan fährt morgen nach Paris" einmal in die Gruppierung "Die Nichte des Nachbarn von nebenan" (das ist sowohl das Ergebnis des Substitutions- wie des Permutationstests) und zum anderen gemäß Substitutionstest in den Rest, nämlich "fährt morgen nach Paris". Speziell der Permutationstest ergibt zusätzlich, daß "fährt morgen nach Paris" seinerseits in drei Gruppierungen zerlegbar ist, zwischen die jeweils andere Gruppierungen treten können:

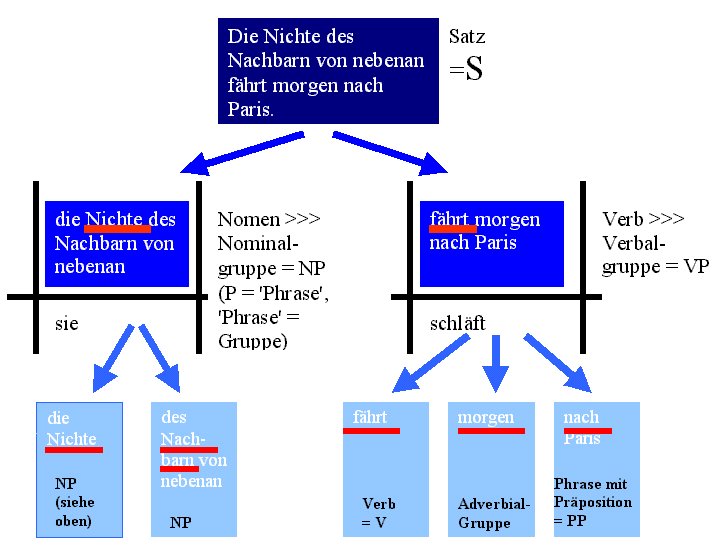
Die obige Darstellung greift auf die mathematische Graphentheorie zurück. Wie der Leser unschwer feststellen wird, ist das Ergebnis der IC-Analyse ein Graph, der zunächst einmal aus Knoten und Kanten hat. Dabei ist ein Knoten ausgezeichnet als Quelle (die Ausgangsäußerung), und die Kanten sind gerichtet (die Relation "zerfällt in" ist nicht umkehrbar). Graphen dieser Art nennen wir STAMMBAUM
.Ich habe die einzelnen Gruppierungen klassifiziert. Die Ausgangsäußerung hat die Form eines Satzes, ihre erste "unmittelbare Konstituente" hat die Form einer Nominalgruppe oder Nominalphrase ("Phrase" = "Gruppe") - warum? Die zweite "unmittelbare Konstituente" hat die Form einer Verbalgruppe - warum? Die Antwort lautet stets: Weil der KOPF dieser Gruppierung immer ein Nomen ist, weil der Kopf dieser Gruppierung immer ein Verb ist - usw. (wir kommen auf die Rede vom Kopf einer Gruppierung gleich ausführlich zurück). - Der Kopf ist jeweils durch einen roten Unterstrich gekennzeichnet.
Was repräsentieren die Knoten des obigen Stammbaums? Positionen (siehe dazu schon weiter oben) oder Gruppierungen bzw. Untergruppen. Was repräsentieren die gerichteten Kanten? Wenn jeweils der übergeordnete Knoten eine (relative) Ganzheit und die jeweils direkt untergeordneten Knoten Teile dieser Ganzheit repräsentieren, dann repräsentieren die Kanten - 'von unten nach oben gelesen' - TEIL-GANZES-RELATIONEN.
Nachdem wir jeweilige Ganzheiten in ihre Teile zerlegt haben, nachdem wir also die einer Äußerung zugrundeliegenden Teil-Ganzes-Relationen bestimmt haben, können wir der Frage nachgehen, welche (generalisierbaren) TEIL-TEIL-RELATIONEN es gibt. Eine in der Sprachwissenschaft wohlbekannte Teil-Teil-Relation ist diejenige, die oben zwischen "die Nichte" und "des Nachbarn von nebenan" besteht: Ich kann wohl sagen "Die Nichte fährt morgen nach Paris", ich kann aber nicht sagen "des Nachbarn von Nebenan fährt morgen nach Paris". Mit anderen Worten setzt das Auftreten der Gruppe "des Nachbarn von nebenan" das Auftreten der Gruppe "die Nichte" voraus. In diesem Fall sprechen wir von Abhängigkeit oder DEPENDENZ - die Gruppe "des Nachbarn von nebenan" ist abhängig oder dependent von "die Nichte".
Ein andere Teil-Teil-Relation betrifft das konjugierte Verb: Ersichtlich hängt es vom jeweiligen konjugierten Verb ab, was im Rahmen einer VP außer dem Verb noch an Gruppierungen auftreten muß (wohlgemerkt "muß", nicht "kann"). Bei "fahren" muß noch eine Gruppe auftreten, die Auskunft darüber gibt, wohin da jemand fährt - andernfalls wäre der Satz grammatisch gesehen unvollständig. Und bei "schlafen" braucht überhaupt nichts weiteres zu folgen. Und bei "stehlen beispielsweise muß außer dem Subjekt und dem konjugierten Verb selber auch eine Gruppe auftreten, die aussagt, wer da etwas gestohlen hat, und eine zweite Gruppe, die aussagt, was denn da gestohlen wurde. Die Schulgrammatik spricht hier auch von der REKTION des Verbs - wir kommen darauf ausführlich zurück.
Ein gerade mit Blick auf kindliche Sprachentwicklungsstörungen intensiv diskutierte weitere Teil-Teil-Relation ist in folgender Äußerung verletzt:
Die Nichte ... fahren morgen nach Paris.Oder man vergleiche
Der Nichten ... fahren morgen nach Paris.Grammatisch falsch sind offensichtlich alle Äußerungen, bei denen (mit Blick auf das zweite Beispiel) der Artikel und das Nomen (und so auch ein attributives Adjektiv) nicht morphologisch in Genus, Numerus und Kasus übereinstimmen. Grammatisch falsch sind darüberhinaus alle Äußerungen, bei denen (mit Blick auf das erste Beispiel) die Nominalgruppe des Subjekts ("die Nichte") nicht morphologisch in Numerus und Person übereinstimmt mit dem konjugierten Verb ("die Nichte" ist dritte Person Singular, entsprechend muß auch das konjugierte Verb in der dritten Person Singular - nämlich "fährt" - auftreten). Wir sprechen hier von MORPHOLOGISCHER KONGRUENZ, die - wie die Beispiele belegen - in zwei Formen für das Deutsche relevant ist.
6.5.3. Exkurs: Morphologische Kongruenz
Die Übereinstimmung z.B. von Subjekt und konjugiertem Verb in Numerus und Person konstituiert innerhalb einer Äußerung einen Zusammenhang unabhängig von der Stellung der betroffenen Morpheme / Wörter und Wortgruppen. Das erlaubt es u.a., die Subjektsnominalgruppe - abhängig von kommunikativen Aussageintentionen - mehr oder weniger überall zu plazieren.
Unabhängig der morphologische Markierungen arbeiten wir bei der Produktion einer Äußerung und bei deren Verstehen aber auch mit nicht-einzelsprachlichen kognitiven Prinzipien der Reihung. Wo immer es geht, setzen wir den in einem Handlungssatz beschriebenen Täter vor die Nennung des Opfers. Gleichartig tendieren wir dazu, Belebtes vor Unbelebtem zu nennen. Das spiegelt sich sehr schön in bestimmten Entwicklungsstadien des kindlichen Spracherwerbs, - Stadien, in denen die Kinder noch nicht der einzelsprachlichen Syntax folgen, sondern mehr oder weniger ausschließlich solche kognitiven Prinzipien der Reihung befolgen.
Kinder mit der sogenannten 'spezifischen Sprachentwicklungsstörung' haben hier in ihrer Entwicklung Schwierigkeiten; sie bleiben viel zu lange bei rein kognitiv gesteuerten Abfolgen (mit dem Verb am Ende) stehen. Ein heute immer noch heiß diskutierter Erklärungsansatz geht davon aus, dass solche Kinder nicht in einem hinreichenden Ausmaß über die für die Kennzeichnung von morphologischen Kongruenzphänomenen nötigen Inventare grammatischer Morpheme verfügen ('lexikalistische These'). Dafür spricht neben spezifischen Abfolgen auch, dass solche Kinder ganz generell nur sehr eingeschränkt Gebrauch von grammatischen Morphemen machen.
Wir können unter Rückgriff auf die Phonetik oben noch einen Schritt weitergehen: Es steht zu vermuten, dass die reduzierten Inventare grammatischer Morpheme zu tun haben damit, dass solche Morpheme nie betont sind, mehr noch: je nach Sprechtempo mehr oder weniger weit abgebaut bzw. verschliffen werden. Mit anderen Worten könnten hier auch auditive Verarbeitungsdefizite eine Rolle spielen, die sich eben gerade bei der Verarbeitung unbetonter Silben besonders stark auswirken.
6.5.4. Zur Rede vom 'Kopf' einer Gruppierung
Gruppierungen wie eine Nominalgruppe oder eine Verbalgruppe haben ein Element, das 'Kopf' der Gruppe ist (nach dem 'Kopf' ist auch die Gruppe benannt, - bei der Nominalgruppe ist das das Nomen, bei der Verbalgruppe das Verb). - Was der 'Kopf' einer Gruppe ist, ist nicht immer leicht zu bestimmen. Am Beispiel der Nominalgruppe gilt, dass der Kern oder das Minimum einer Nominalgruppe immer ein Nomen wie beispielsweise "Emil" oder ein Pronomen ist. Die minimale Ausgestaltung einer Verbalgruppe ist das Verb.
Bei einer Präpositionalgruppe oder Präpositionalphrase nimmt man an, dass die Präposition der 'Kopf' ist. Allerdings steht bei dieser Überlegung nicht so sehr die minimale Ausgestaltung im Vordergrund, denn eine Präpositionalgruppe kann ja nicht auf eine Präposition verkürzt werden. Sondern hier steht im Vordergrund, dass es die Präposition ist, die den Kasus des dann folgenden Nomens (plus Artikel, eventuell plus attributives Adjektiv) bestimmt. Das ist auch ein Argument, dass für die Verbalgruppe aufgeführt wird; auch hier ist es das Verb, das die Zahl und die morphologischen Charakteristika einer Reihe noch folgender Nominal- und Präpositionalgruppen bestimmt (wir hatten das als Teil-Teil-Relation bzw. als Rektion des Verbs oben bereits kennen gelernt; aus der Rektion ausgeschlossen war jeweils das Subjekt).
Bei näheren Angaben zu Ort und Zeit begegnen uns sowohl Adverbialgruppen (minimale Ausgestaltung: ein Adverb des Ortes oder der Zeit wie "morgen") als auch Präpositionalgruppen wie "in zwei Wochen". Hier steht in Frage, ob es sich nicht um den gleichen Typ von Gruppierung handelt und man auch Präpositionalgruppen wie "in zwei Wochen" als Adverbialgruppen führen sollte (denn - wie gesagt - die minimale Ausgestaltung ist ein Adverb wie "morgen").
Bei Nominalgruppen - so wird überlegt - könnte es sich auch um Artikelgruppen (Artikel = Determinans) bzw. Determinantengruppen handeln, - warum? Nomina treten auch rein prädikativ bzw. als Teil einer Verbalkonstruktion auf, - man vergleiche
Er ist Freiburger wie du und ich.
"Freiburger" wird rein prädikativ, nicht aber 'nominal' gebraucht; der Ausdruck referiert nicht auf jemanden, der in Freiburg geboren wurden und / oder dort wohnt, sondern der Sprecher sagt damit gewissermaßen eine Eigenschaft aus; das begründet auch, warum dieses Nomen nicht durch einen Relativsatz erweiterbar ist. Mit einem Nomen auf ein Stück Wirklichkeit referieren und dieses Nomen durch einen Relativsatz erweitern kann ich nur, wenn das Nomen durch einen Artikel als tatsächlich 'nominal' verwendetes Nomen gekennzeichnet ist, - vgl. die folgenden zwei Beispiele, bei denen ein vorangestelltes Sternchen festhält, dass native speaker die betreffende Äußerung für grammatisch falsch halten:
* Er ist Freiburger, der seine Stadt bestens kennt.Er ist
ein Freiburger, der seine Stadt bestens kennt.Mit anderen Worten ist es in einer Nominalgruppe der Artikel, der kennzeichnet, ob das beteiligte Nomen tatsächlich in der genuinen, für Nomina und Nominalgruppen charakteristischen Funktion auftritt; es ist der Artikel, der festhält, dass hier ein Sprecher tatsächlich auf ein Stück Wirklichkeit referiert.
6.6. Valenz, Rollen, Diathese6.6.1. Grundlagen der Valenztheorie
Wir hatten oben eine Reihe von Teil-Teil-Relationen wie die morphologische Kongruenz oder Abhängigkeit bzw. Dependenz angesprochen. Eine ganz zentrale Teil-Teil-Relation ist die VALENZ, wobei wir uns hier auf die Valenz der Verben konzentrieren (auch Substantive oder vor allem Adjektive können eine Valenz haben). - Was ist mit Valenz gemeint?
Die chemische Formel für Wasser lautet H2O. Die graphische Wiedergabe macht deutlich, dass wir es hier einmal mit einem Sauerstoffatom (= O) und zwei Wasserstoffatomen (= H) zu tun haben. Die Formel bzw. deren graphische Wiedergabe unten beinhaltet aber noch mehr Information: Es ist das Sauerstoffatom, dass zwei offene Bindungsstellen hat; an jeder dieser Stelle bindet das Sauerstoffatom ein Wasserstoffatom; die Wasserstoffatome binden nicht ihrerseits, sondern sind vom Sauerstoffatom gebunden:
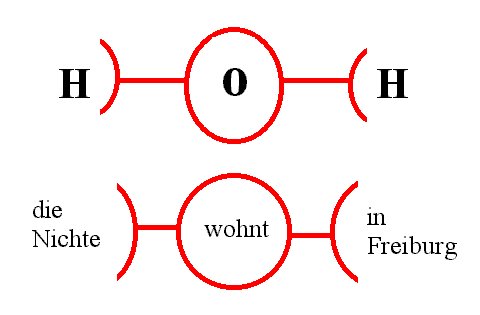
Terminologisch sprechen wir in Parallele zur Vorlage H2O von der WERTIGKEIT eines Verbs, hier des Verbs "wohnen"; und zwar ist "wohnen" zweiwertig, d.h. es bindet zwei weitere Ausdrücke bzw. Gruppierungen, hier einmal "die Nichte", zum anderen "in Freiburg".
In Anlehnung an die Valenztheorie des Franzosen Tesnière sprechen wir von den gebundenen Ausdrücken oder Gruppierungen als AKTANTEN; "die Nichte" und "in Freiburg" sind Aktanten. - In geeigneten Kontexten müssen nicht alle von einem Verb eröffneten Leerstellen auch besetzt sein; beispielsweise könnte bei einer Sammlung des Roten Kreuzes die eine Nachbarin zur anderen Nachbarin sagen: "Ich habe einen größeren Geldbetrag gespendet". Es ist aber völlig klar, dass der Stellenplan des Verbs "spenden" drei Leerstellen eröffnet: Jemand spendet jemandem etwas. Im obigen Kontext ist es aufgrund der Kontextinformation jedoch erlaubt, auszulassen, wem die Nachbarin hier "einen größeren Geldbetrag" gespendet hat. Mit anderen Worten handelt es sich bei "dem Roten Kreuz" (oben ausgelassen) um einen FAKULTATIVEN AKTANTEN, hingegen ist "ich" ein OBLIGATORISCHER AKTANT; - das sind Aktanten, die immer auftreten müssen, damit wir als native speaker den Satz als grammatisch vollständig empfinden. - Und was ist mit "einen größeren Geldbetrag"? Hier handelt es sich wohl ebenfalls um einen fakultativen Aktanten, denn auch das könnte ich in geeigneten Kontexten auslassen.
Nun können über die vom Verb gebundenen Ausdrücke bzw. Gruppierungen hinaus auch Ausdrücke frei dazugestellt werden, so etwa "Gestern habe ich dem Roten Kreuz einen größeren Geldbetrag gespendet" oder "Gestern habe ich in Freiburg meinen ehemaligen Deutschlehrer gesehen". Frei hinzugestellt deshalb, weil eben "spenden" nicht heißt "jemand spendet irgendwann irgendjemandem irgendetwas", und auch "sehen" heißt nicht "jemand sieht irgendwann irgendwo etwas/jemanden". Anders ausgedrückt ist ein Verb wie spenden dreiwertig, nicht aber vierwertig, und "sehen" ist zweiwertig, nicht aber vierwertig. - Bei frei hinzugestellten Ausdrücken bzw. Gruppierungen sprechen wir in Anlehnung an Tesnière von ZIRKUNSTANTEN.
Wieviel wertig ist das Verb "glauben"? Hier sind verschiedene Antworten möglich, denn "glauben" ist mehrdeutig, wenngleich die einzelnen Bedeutungen sich teilweise stark ähneln. Wir sprechen hier von den Lesarten des Verbs, - viele Verben haben mehrere Lesarten. Die Frage nach der Wertigkeit kann ich bei mehreren Lesarten aber nur pro Lesart beantworten, und das gilt auch für eine Reihe weiterführender Fragen.
Das Verb "glauben" kann bedeuten
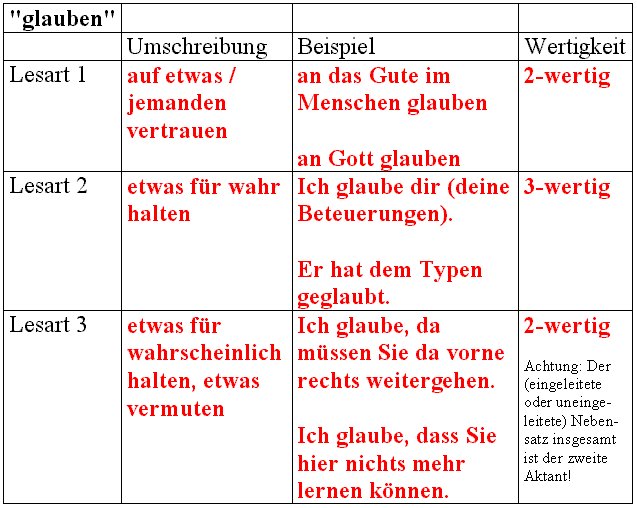
Die Valenz eines Verbs umfaßt aber noch mehr als nur (möglicherweise) verschiedene Lesarten und pro Lesart eine jeweilige Wertigkeit. Wenn ich mir ein Verb wie "wohnen" aus dem Lexikon wähle, dann weiß ich auch sofort, wer da nur in Frage kommen kann als jemand, der "glaubt"; ein Stein kann nicht glauben, dass etwas der Fall ist, er kann auch nicht an das Gute im Menschen glauben, und das kann auch kein Tier, es sei denn, wir verwenden "glauben" metaphorisch und 'vermenschichen' das Tier, z.B. den Fuchs oder den Raben, - so in den Fabeln von Jean de la Fontaine:

Mit anderen Worten wissen wir über die Wertigkeit hinaus auch - erneut am Beispiel von "glauben": dass einer der Aktanten - im Aktiv der Subjektsaktant - immer <menschlich> sein muß. Vergleichbar glaube ich immer einem Menschen, dass etwas wahr ist. Und was ist es, das wahr sein kann? Das kann immer nur ein Sachverhalt im weitesten Sinne sein, nie ein konkreter Gegenstand oder ein Person (wenn wir von einer Person sagen, dass sie wahr sei, dann meinen wir eine zweite, andere Bedeutung von "wahr", - "wahr" soviel wie "echt", "mit sich übereinstimmend", nicht "in Kern und Fassade auseinanderfallend").
Wir wissen sogar noch mehr, - wir wissen bei Abwahl eines Verbs - hier jetzt wieder am Beispiel "wohnen" - auch, wie die Subjektsaktanten morphologisch aussehen müssen: Stets handelt es sich um ein Nomen/Pronomen bzw. um eine Nominalgruppe. Und der zweite Aktant von "wohnen" - die Ortsangabe, die gefordert ist, muß morphologisch beschrieben entweder ein Adverb (z.B. "hier") oder eine Präpositionalgruppe (z.B. "in Freiburg") sein.
Zusammenfassend gehört zu den fest mit einem Verb verbundenen Valenz-Informationen auch, welche SEMANTISCHEN RAHMENBEDINGUNGEN und welche MORPHOLOGISCHEN RAHRMENBEDINGUNGEN oder Klassifikationen pro Aktant gelten. Das läßt sich mit den oben diskutierten Aspekte wie folgt schematisch zusammenfassen:

Ein besonderer Typ von Lexikon listet die Verben samt ihren Valenzbedingungen auf (siehe die letzte Abbildung); wir sprechen hier von Valenzwörterbüchern, die neben den semantischen (de Saussure: 'konzeptuellen') Informationen auch viele morphosyntaktische Informationen zusammenstellen. Im Grunde genommen liefert der Eintrag in einem Valenzwörterbuch gleich eine ganze Satzstruktur mit.
Ein Wort zum praktischen Nutzen von Valenzwörterbüchern: Zieht man im Rahmen von Übersetzungen ein Valenzwörterbuch der Zielsprache zu Rate (z.B. Französisch), so liefert dieses einem sofort die Struktur ganzer Sätze, und man vermeidet gegebenenfalls gravierende Grammatikfehler, wie sie vorliegen, wenn ich etwa "jemand glaubt jemandem etwas" mit frz. "croire" übersetze: Man kann im Französischen nur "etwas glauben" ODER "jemandem glauben" und muß den dritten Aktanten des deutschen Verbs mithilfe eines eigenen Konstruktion - z.B. mithilfe eines neuen Teilsatzes - übersetzen. Man vergleiche hierzu das Valenzwörterbuch der Verben des Französischen von Busse / Dubost:



etw glauben, jm glauben
... Que croire? Qui croire?
... Qui, Monsieur, je vous crois sur parole. Croyez-vous ce
qu'il dit? C'est vrai, croyez moi. Je ne crois pas un traître
mot de ce que vous ...
Im Rahmen des Sprachproduktionsmodells von Levelt (auf den wir weiter unten ausführlicher zu sprechen kommen) spielt eine Vorstellung von Lexikon eine wichtige Rolle, die dem hier beschriebenen Format eines Valenzwörterbuchs ein gutes Stück weit entspricht. Neben konzeptueller Information ('Bedeutung') spielen morphosyntaktische Informationen und dann zusätzlich noch ein dritter Typus von Information eine Rolle.
Bei diesem dritten Typus geht es um das, was de Saussure die 'reziproke Evokation' von "image" und "concept" nannte: Wie kommt ein native speaker nach Abwahl eines bestimmten Gehaltes (de Saussure: "concept", bei Levelt zusätzlich morphosyntaktische Informationen) zu der dazugehörenden Wortform (de Saussure: "image", heute - im Gefolge Levelts - auf Deutsch "Wortform")? De Saussure hatte - mit neurowissenschaftlichen Begriffen geredet - von der automatischen 'Mit-Aktivation' eines "image" (bzw. bei der Aktivierung eines "image" von der automatischen 'Mit-Aktivation' eines "concept") gesprochen. Levelt modelliert das eher in Anlehnung an die Arbeitsweise eines Computers und spricht von Adresse: Im Wortinhaltslexikon bzw. als Teil eines Inhaltseintrags (de Saussure: "concept", bei Levelt zusätzlich morphosyntaktische Informationen) ist eine Adresse für eine passende Wortform (de Saussure: "image") im Wortformenlexikon (dieses als Speicher mit adressierten Plätzen) gespeichert. Entsprechend kann ich auf einer bestimmten Stufe der Sprachproduktion auf das Wortformenlexikon zurückgreifen und finde dort entsprechend der Adresse auf einem spezifischen adressierten Platz des Wortformenlexikons die mich interessierende Wortform.
Wenn jemand dem Roten Kreuz einen größeren Geldbetrag gespendet hat - oder schlimmer noch: wenn ein junger Mann einer alten Frau die Handtasche gestohlen hat, dann kann sich der Richter, der die entsprechende Anklage verhandelt, nicht damit begnügen, festzuhalten, dass sowohl die Aktantenstelle von "ein junger Mann" wie die Aktentenstelle von "einer alten Frau" je menschliche Aktanten erfordert. Sondern dann will er - sehr viel entscheidender - wissen, wer der Täter (und wer das Opfer) ist. Mit anderen Worten - so könnten wir das als Kritik festhalten - greift eine Beschreibung von Aktanten, aber genauso von Zirkumstanten, einfach zu kurz, wenn sie sich mit semantischen Charakteristika wie <menschlich> zufrieden gibt.
Die hier angesprochenen Überlegungen gehen auf teilweise sehr alte Vorstellungen der Sprachwissenschaft zurück. Schon Panini (4. Jhd. v. Chr.; Grammatik des Sanskrit) versuchte, den Bedeutungszusammenhang einer Äußerung bzw. eines geäußerten Satzes ganzheitlich zu erfassen. Er spricht von Sätzen als kleinen Dramen mit definierten Rollen, sog. Ka:rkas. Diese Rollen (wir sprechen heute von semantischen Rollen, gleichbedeutend auch von Theta-Rollen) werden auf bestimmte Weise auf grammatische Elemente eines Satzes abgebildet (wir kommen auf diese Vorstellung von der Abbildung semantischer Rollen auf grammatische Elemente eines Satzes unter dem Stichwort der Diathese zurück).
Der amerikanische Linguist Charles Fillmore hat 1968 solche Überlegungen aufgegriffen (zunächst spricht er noch von 'semantischen Kasus', später dann von semantischen Rollen). Dabei folgt er der Idee, dass dieselbe semantische Rolle morphosyntaktisch unterschiedlich realisiert werden kann; auch hier ist implizit bereits die Vorstellung greifbar, dass semantische Rollen auf je verschiedene grammatische Elemente eines Satzes abgebildet werden können.
Nochmals: Der Kern solcher Vorstellungen ist, dass gewissermaßen jeder Satz neben anderen Bedeutungsaspekten die Szene eines Theaterstücks wiedergibt, und eine solche Szene läßt sich als Ensemble von semantischen Rollen aus einem letztlich universellen und hochgradig begrenzten Inventar semantischer Rollen verstehen. Beispielsweise ist eine typische Diebstahlsszene definierbar als Ensemble dreier beteiligter Rollen: Da ist einmal der Dieb (der Täter - in der Terminologie der semantischen Rollentheorie = AGENS), - ohne Dieb kein Diebstahl! Dann wurde jemand bestohlen, - das Opfer (in der Terminologie der semantischen Rollentheorie = PATIENS), - wenn keiner bestohlen wurde, kann es sich auch nicht um Diebstahl handeln. Und schließlich muß dem Opfer etwas abhanden gekommen sein (in der Terminologie der semantischen Rollentheorie das SEMANTISCHE OBJEKT), - wenn nichts abhanden gekommen ist, kann es sich ebenfalls nicht um Diebstahl handeln.
Die Rollentheorie kennt auch Rollen wie INSTRUMENTAL - beispielsweise kann jemand eine Schaufensterscheibe mit einem Hammer eingeschlagen haben. Insgesamt glaubt die semantische Rollentheorie mit etwa sieben bis neun Rollen auskommen zu können, um auf diese Weise für alle natürlichen Sprachen der Welt die jeweils in Äußerungen realisierten semantischen Szenen zu beschreiben. Wichtig ist in diesem Zusammenhang, dass die Rollentheorie ihre Rollen als universale Größen versteht, - zwar sprachlicher, aber eben vor- oder außereinzelsprachlicher Natur.
Ein- und dieselbe semantische Szene, ein- und dasselbe Gefüge semantischer Rollen kann in einer Einzelsprache wie dem Deutschen ganz unterschiedlich realisiert werden, kann auf ganz unterschiedliche (einzelsprachliche) morphosyntaktische Strukturen abgebildet werden. Wir rücken im Folgenden die Genus verbi, die 'Genera des Verbs' (Aktiv, werden-Periphrase bzw. werden-Passiv, bekommen-Periphrase) in den Mittelpunkt der Betrachtung (es gibt darüberhinaus aber noch weitere, allerdings nicht in gleicher Weise 'grammatikalisierte' bzw. in die Grammatik des Deutschen fest eingebaute, Möglichkeiten):
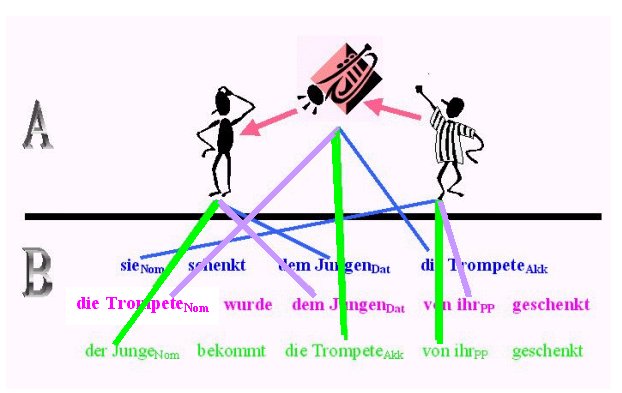
Oben (= A) haben wir links "den Jungen", rechts "sie" (im gestreiften Hemd) und in der Mitte "die Trompete"; die Graphik soll festhalten, dass es sich um eine zwar universell-sprachliche oder mentale Repräsentation handelt, die aber (noch) nicht einzelsprachlich - hier: in deutscher Sprache - realisiert ist. Unten dann (= B) haben wir die drei 'diathetischen Möglichkeiten' des Deutschen, nämlich Aktiv, werden-Periphrase und bekommen-Periphrase.
Wollte man den Zusammenhang etwas formaler (und zugleich generalisiert) ausdrücken, dann wie folgt:
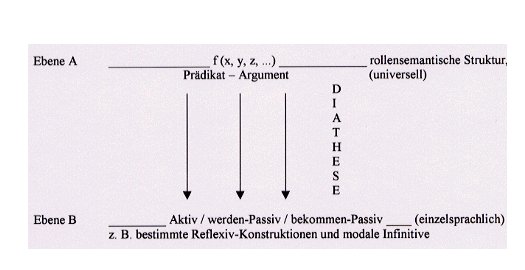
Die obige Wiedergabe hält u.a. fest, dass die rollensemantische Struktur auf Ebene A heute auch als prädikatenlogische Struktur dargestellt wird; eine Notation wie "(f(x,y,z)" hält fest, dass hier ein semantisches Prädikat mit drei Argumenten bzw. Argument-Rollen verbunden ist. Die Darstellung weist darüberhinaus für die Ebene B weitere einzelsprachliche bzw. deutsche Realisierungsmöglichkeiten auf, so etwa gewisse Reflexiv-Konstruktionen oder gewisse modale Infinitive. - Ein Beispiel für eine solche Reflexiv-Konstruktion ist der Satz "Das Buch liest sich gut": Hier liegt als 'Szene' zugrunde, dass 'jemand ein Buch liest' und über das Buch urteilt; man könnte geradezu von einer 'passivischen Perspektive' sprechen. - Ein Beispiel für einen modalen Infinitiv wäre:
A: "Darf ich euer Auto benutzen?"
B: "Aber bitte, das Auto ist zum Benutzen da / das Auto ist da, um benutzt zu werden."
Hier liegt als hypothetische Szene zugrunde, dass 'jemand das Auto benutzt'; auch hier könnte man geradezu von einer Passiv-ähnlichen Perspektive sprechen.
6.6.6. Zur besonderen (diathetischen) Leistung des Subjekts
Auf die Frage, wozu eine natürliche Sprache unterschiedliche diathetische Abbildungsmöglichkeiten - so das werden-Passiv - braucht, wird heute als Antwort formuliert: Um unterschiedliche Ausschnitte einer zugrundeliegenden rollensemantischen Struktur (bzw. unterschiedliche Ausschnitte der zugrundeliegenden Szene) zum Subjekt machen zu können, um auf diese Weise ein- und dieselbe rollensemantische Struktur mit einer je anderen Perspektive wiedergeben zu können. Wie das?
Ich stelle im folgenden einige Tests vor, die uns helfen können, auf die obige Frage eine Antwort zu finden. - Im folgenden Test arbeiten wir mit zwei Bildelementen, einer Linie und einem Stern:
Linie:
Stern:
Bitte beschreiben Sie mithilfe eines einfachen Aussagesatzes das Verhältnis der beiden Bildelemente in der folgenden Graphik:

Es gibt noch einen zweiten Grund, - Tests haben ergeben, dass für dasjenige, was oben ist, stets ein höheren Salience-Wert gilt als für dasjenige, was unten ist. Und in der Tat fallen die Ergebnisse gleich deutlich schwächer aus (jetzt machen nur noch etwa 69% der Versuchspersonen den Stern zum Subjekt), wenn man den Stern unter die Linie setzt und nun wieder einen einfachen Aussagesatz erbittet, der die räumliche Lage der beiden Bildelemente zueinander beschreibt.
Im folgenden Test ist es die persönliche Betroffenheit, die über den Salience-Wert eindeutig entscheidet. - Stellen Sie sich vor, Sie kämen zusammen mit Kommilitonen oder Kommilitoninnen aus der Universität; dem Haupteingang gerade gegenüber eine Laterne, an die Sie Ihr Fahrrad angeschlossen hatten. Und nun ist das Fahrrad - samt Schloß - verschwunden. Welche der folgenden Formulierungen würde Sie - eher verblüfft als geschockt - wählen:

Der weitaus größte Teil der Versuchspersonen wählte eine Formulierung mit "Fahrrad" als Subjekt. Mit anderen Worten ist es zunächst einmal nebensächlich, dass jemand - und wer - das Fahrrad gestohlen hatte; kognitiv im Mittelpunkt stand das Fahrrad, das nicht mehr da war. Eben das meint aber die Rede von der je anderen Perspektive, mit der wir auf eine Szene schauen, mit der wir eine rollensemantische Struktur einzelsprachlich verbalisieren.
6.7. Das Sprachproduktionsmodell von LeveltDie Diathese liefert uns - dynamisch als Überführung oder Abbildung oder 'Übersetzung' gedacht - das Kernstück eines Sprachproduktionsmodells. Und zwar eines Modells, das derzeit weitgehend die Diskussion um die Modellierung der Sprachproduktion beherrscht, - ich meine das Sprachproduktionsmodell von Levelt.
Im folgenden werden die zwei mit der Diathese thematisierten Sprachverarbeitungsebenen in den Modellzusammenhang des Levelt-Modells integriert:
SCHRITT 1
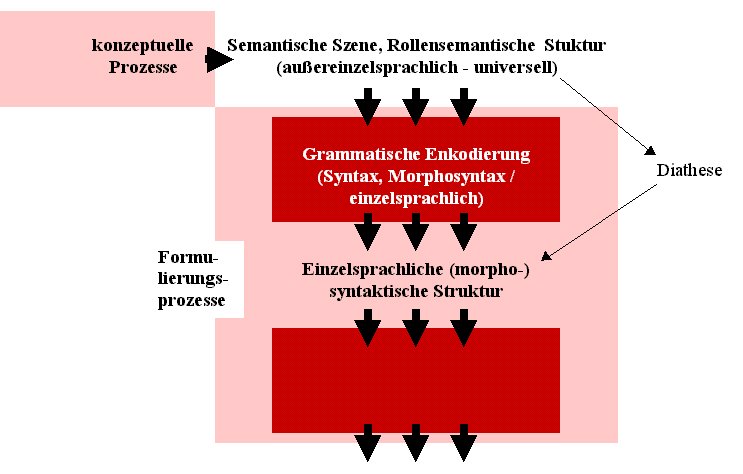
Wir gehen im folgenden auf die konzeptuellen Prozesse nicht näher ein. Wir wollen nur festhalten, dass Levelt sein Modell zu Anfang sehr stark in Parallele zur Arbeitswesie eines Computers ausgestaltet hat. Die Kästchen - so die konzeptuellen Prozesse - geben so etwas wie Prozessoren wieder, und vorweg und danach ist jweils der Input bzw. Output notiert. Entsprechend ist eine jeweilige rollensemantische Struktur Output der konzeptuellen Prozesse und zugleich Input für die Formulierungsprozesse. Genauer ist bei den Formulierungsprozessen ein Ausschnitt betroffen, die einzelsprachliche grammatische Enkodierung, - ein Prozessor, der aus dem Input eine einzelsprachliche (morpho-)syntaktische Struktur ableitet (dasjenige also, was wir im Rahmen der zwei Ebenen A und B der Diathese auf Ebene B notiert hatten).
Was hier fehlt, ist das Lexikon. Wir hatten bereits oben angesprochen, dass inhaltsseitig im Leveltschen Lexikon nicht nur Bedeutungen (nach de Saussure ein jeweiliges concept) gespeichert sind, sondern - ähnlich wie beim Valenzwörterbuch - auch syntaktische Informationen. Und es kommt eine Adresse für eine Wortform hinzu, die es an späterer Stelle erlaubt, anstelle des Inhaltseintrags eine dazu passende Wortform aufzurufen und einzusetzen:
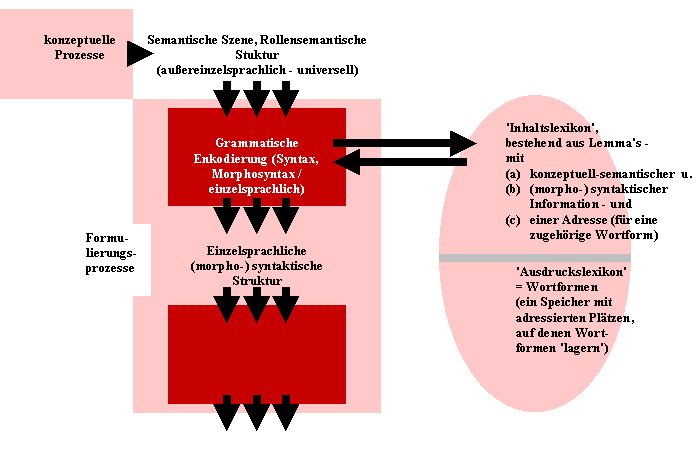
Wenn man an morphosyntaktischer Information zugrundlegt, was ein Valenzwörterbuch pro Eintrag festhält, dann liefert ein jeweiliges Lemma (= Eintrag im 'Inhaltslexikon') grundlegende Informationen zum Aufbau von Satzstrukturen. Was allerdings zum Subjekt gemacht werden soll - und damit auch: ob ein Aktiv oder etwa ein werden-Passiv gewählt wird, das ist bereits im Input für die grammatische Enkodierung mit festgelegt (anders: darüber kann ein Eintrag aus dem 'Inhaltslexikon' keine Auskunft geben).
Wenn wir uns eine einzelsprachliche morphosyntaktische Struktur als Stammbaum vorstellen (vgl. oben die IC-Analyse), dann befinden sich am Ende des Stammbaums lauter Lemma's. Damit der (lautsprachliche) Sprachproduktionsprozess weitergehen kann, müssen an dieser Stelle die Lemma's durch dazu passende Wortformen aus dem 'Ausdruckslexikon' ersetzt werden; das sind Phonemfolgen, in seltenen Fällen auch einzelne Phoneme.
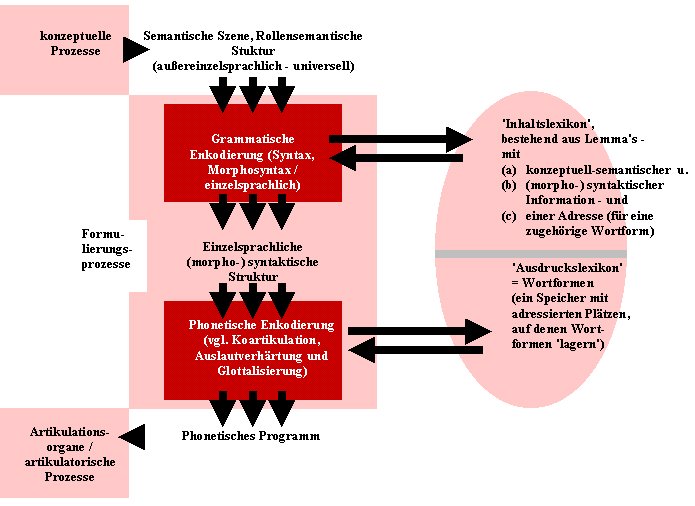
Wir sprechen unten mit Blick auf den Prozessor, der in Ersatz eines Lemma's eine Wortform aufruft und in eine morphosyntaktische Struktur 'einträgt', von der phonetischen Enkodierung (Levelt selber spricht allerdings mit Blick auf die Phonemfolgen im 'Ausdruckslexikon' von phonologischer Kodierung); warum "phonetisch"? Die wichtigste Aufgabe ist nicht der Austausch eines Lemma's durch eine Wortform, eine Phonemfolge, sondern die Überarbeitung entsprechender Phonemfolgen - derart, dass sie entsprechend der für eine Einzelsprache geltenden Normen auch artikuliert werden können. Beispielsweise muß sicher gestellt werden, dass die Phonemfolge
/g l y k / = "Glück" (etwa in "Das hast du aber noch einmal Glück gehabt") nicht als Abfolge der einzelnen Phoneme artikuliert wird. Vielmehr ziehen wir im Standarddeutschen die Ausbildung eines zusätzlichen Ansatzrohrs mit den Lippen - als Teil der Artikulation von / y / - bereits in die Artikulation des eröffnende Verschlußlautes / g / hinein. Vergleichbar neigen wir im Standarddeutschen dazu, auch bereits das Einrollen der Zunge - als Teil der Artikulation von / l / - in die Artikulation des eröffnenden Verschlusses hineinzuziehen. Wir sprechen hier von Koartikulation.Vergleichbar artikulieren wir einen Lenis-Frikativ oder Lenis-Verschluß im offenen Auslaut einer Silbe oder eines Wortes (dann also, wenn im Rahmen der Silbe oder des Wortes kein Vokal folgt) als fortis-Laut, - vgl. das Verb "jagen", das als Substantiv "Jagd" mit [ k ] gesprochen wird. Oder man betrachte das altertümliche Verb "sich laben", das wir im offenen Auslaut mit einem fortis-Verschluß artikulieren, vgl. "Du labst dich an meinem Anblick" (mit [ p ] ). Wir sprechen hier von der Auslautverhärtung des Standardeutschen. Ein drittes Beispiel für die Überarbeitung einer Wortform sind Einträge im 'Ausdruckslexikon', die mit einem Vokal beginnen, - man vergleich eine Wortform wie "um" - etwa in "um den Baum her-um": Wenn ein solcher Eintrag im offenen Anlaut auftritt (also nicht durch einen Konsonanten gleichsam 'gedeckt' ist - so die Präposition zu Anfang), dann setzen wir einen Glottisverschluß voran; wir sprechen hier auch von der Glottalisierung des Standarddeutschen.
Zusammengenommen ergibt das die folgenden Präzisierungen:
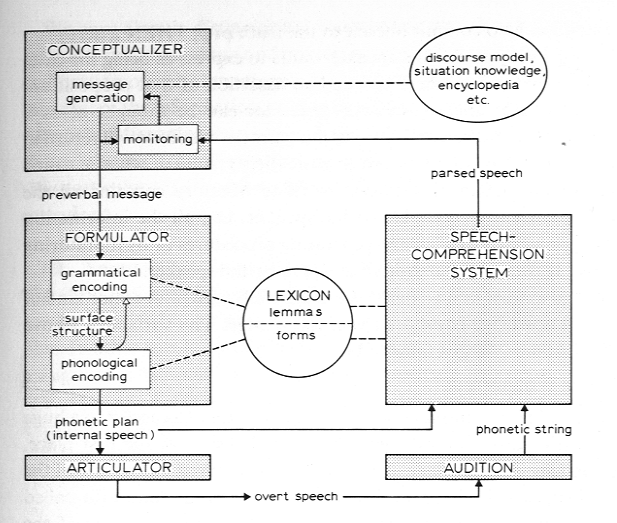
Die obige Wiedergabe ist ein Ausschnitt aus dem Levelt-Modell. Es fehlt, was Levelt an Modellteilen für die Rezeption hinzugefügt hat. Und unser Ausschnitt oben beinhaltet nicht eine Reihe kleiner Erweiterungen, die Levelt und seine Schüler seit der ersten Publikation erarbeitet haben.
Die angedeuteten Erweiterungen sind für eine Einführung jedoch unwichtig. Nichts desto weniger füge ich im Anschluß einen vollständigen Modellüberblick hinzu, der jedoch nicht weiter diskutiert werden soll:
7. Probeklausuren
(1) Was sind indexikalische Zeichen? Geben Sie ein Beispiel.
(2) Was verstehen wir unter apperzeptiver Ergänzung? Erläutern Sie den Begriff mit einigen wenigen Sätzen. Geben Sie ein Beispiel. Wer hat den Begriff eingeführt?
(3) Wo liegt der primär-auditorische Cortex?
(4) Beschreiben Sie 'nach allen Regeln der Kunst' den für das Deutsche so typischen r-Laut (am Beispiel des anlautenden "R" in "Rachengold").
Zu (1): Ein Index ist ein Zeichen, und zwar ein solches, das kausal mit dem Bezeichneten (demjenigen, 'wofür es steht') in Verbindung steht. Beispiel ist (oder kann sein) eine heiße Stirn, diese als Zeichen (nämlich Index) für Fieber (Fieber z.B. als Teil einer Grippe). Vergleichbar signalisiert Rauch (als Index) Feuer. Für die heiße Stirn gilt dabei, dass sie zugleich Teil des Fiebergeschehens ist, das sie durch das Fieber verursacht ist. Vergleichbar ist Rauch durch das Feuer verursacht.
Der Begriff stammt von Peirce, der neben dem Index noch das Icon und dann Symbole kennt, auf die hier aber nicht näher eingegangen werden soll.
Zu (2): "Apperzeptive Ergänzung" meint ganz generell Vervollständigung eines sensorischen Eindrucks (oder Inputs) unter Rückgriff auf so etwas wie 'Musterwissen'.
Der Begriff geht auf Bühler und sein Organon-Modell zurück, - man vergleiche die folgende Darstellung:

Hier gibt das Dreieck die Funktionen von Zeichen wieder, der Kreis hingegen die materiale Realisierung oder Gestalt. Das Verhältnis der beiden Figuren 'Kreis' und 'Dreieck' soll u.a. festhalten, dass eine Zeichengestalt häufig lückenhaft ist (gemeint sind jene Teile, in denen das Dreieck, also die Funktionen oder die Bedeutung, über das Dreieck hinausgehen). Man denke etwa an die Schwarz-Weiß-Strichzeichnung eines Gegenstandes, z.B. eines Staubsaugers, die ja nur einen Bruchteil derjenigen optischen Eigenschaften realisiert, die einen Staubsauger tatsächlich ausmachen.
In der Neurolinguistik wird das relevant bei der Untersuchung der bei einer Alzheimer-Krankheit schon sehr früh begegnenden Benennstörungen, - üblicherweise mit Schwarz-Weiß-Strichzeichnungen von Gegenständen überprüft. Entsprechende Patienten zu zu apperzeptiven Ergänzungen nur noch tendenziell in der Lage. Reichert man allerdings die Vorlagen an (z.B. Farbphotos) oder läßt Realien benennen, dann steigt die Benennleistung signifikant (dann werden ausführliche apperzeptive Ergänzungen überflüssig).
Zu (3): Die primär-auditorischen Gebiete sind Teil des Cortex, des Großhirns; es gibt in jeder Hemisphäre - in jedem der beiden Cortex-Teile - ein solches Zentrum, die über Kreuz den Input aus den Ohren verarbeiten (das rechte primär-auditorische Areal den Input aus dem linken Ohr und umgekehrt). Dabei liegen die beiden primär-auditorischen Areale in Höhe der sog. Zentralfurche direkt unterhalb der sog. Sylvischen Furche. - Die folgende graphische Wiedergabe zeigt die linke Hemisphäre und hier die Lage des linken primär-auditorischen Areals (das den Input aus dem rechten Ohr verarbeitet):
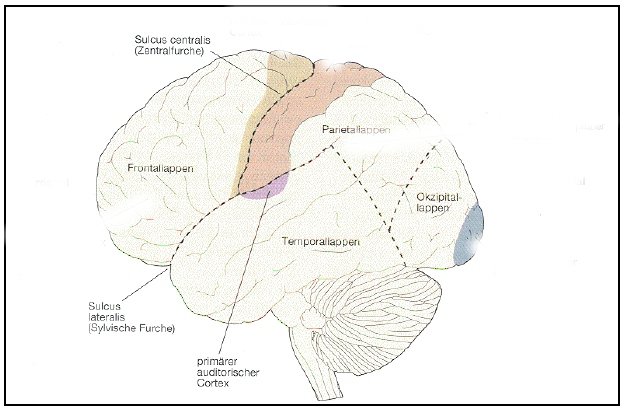
Zu (4): Der standarddeutsche r-Laut (wie das "R" in "Rachengold") ist I = ein Frikativ-Laut, II = lenis, III = stimmhaft, IV = velar artikuliert wird.
Auf der Bühne kennen wir auch das 'Bühnen-r'. Hier wird um der besseren Hörbarkeit statt lenis ein Fortislaut artikuliert. Dabei führt der deutlich höhere Luftdruck und die auf diese Weise stark erhöhte Strömungsgeschwindigkeit, mit der die Luft die betreffende Enge durchströmt, dazu, dass das weiche Velum-Gewebe mitgerissen wird; aus dem Frikativ-Laut entsteht ein Vibrant.
7.2. Probeklausur 2Bearbeiten Sie die folgenden Aufgaben:
(1a) In welcher Region des Großhirns (= Cortex) sind vermutlich die komplexen artikulatorischen Bewegungsentwürfe gespeichert, denen ich folge, wenn ich z.B. "(Da haben Sie ja nochmal) Glück (gehabt)" ausspreche?(1b) Was ist im Kontext des Beispiels aus (1a) das Besondere an der Artikulation des anlautenden Verschlusses?
(2a) Beschreiben sie (mit phonetisch-artikulatorischen Begriffen), um was für einen Laut es sich bei [ ç ] in [ I ç ] handelt. (2b) "(Du) redest (daher, als ob du von nichts wüßtest!)": Analysieren sie morphologisch "redest"! Zu (1a): Vermutlich sekundär-motorische Regionen (vor den primär-motorischen Regionen gelegen), in der Nähe der Sylvischen Furche (also die Broca-Region), in der dominanten (üblicherweise linken) Hemisphäre. Zu (1b): Wir ziehen in die Verschlußbildung hinein (a) die Ausbildung eines mit den Lippen gebildeten 'Ansatzrohrs', die an sich erst zur Artikulation von "ü" gehört, und (b) biegen wir (zeitlich leicht nach dem Vorstülpen der Lippen) die Zungenspitze nach oben, wie das eigentlich erst zum artikulatorischen 'Programm' des "l" gehört (wir können hier auch von 'Koartikulation' sprechen). Zu (2a): Es handelt sich um einen Frikativ, fortis - stimmlos, palatal gesprochen, der sog. "ich-Laut"; der "ich-Laut" und sein velares 'Gegenstück', der sog. "ach-Laut", bilden zwei Allophone ein- und desselben Phonems. Zu (2b): Die Substitutionstests (paradigmatische Ersetzungsversuche) ergeben als Segmentation "red-" + "-/-" + "est". Dabei ist "red-" der Verbstamm (mit entsprechender lexikalischer Bedeutung); das 'Null-Segment' in der Mitte drückt Präsens aus (in Opposition zu einem "-t-", das Präteritum ausdrücken würde); und "-est" ist ein Allophon (zweites Allophon: "-st") des 2.Pers.Sg.-Morphems. - Die Allomorphe "-st" und "-est" sind komplementär verteilt, abhängig vom lautlichen Kontext. Genauer wird durch Einschieben eines Restvokals ("e") verhindert, dass an der Morphemgrenze zwei ortsgleich artikulierte Konsonanten direkt aufeinandertreffen und verschliffen werden. 7.3. Probeklausur 3(1) Erläutern Sie die 'doppelte Gliederung' (Martinet) natürlicher Sprachen. Inwiefern ist diese ökonomisch?
(2) Die Gesamtbedeutung von "zweihundert" ist komplex; aus welchen Bestandteilen setzt sie sich - auf welche Weise - zusammen?
(3) Nennen Sie ein Beispiel für syntaktische relevante grammatische Morpheme. Erläutern Sie auch, was mit 'morphologischer Kongruenz' gemeint ist.
Zu (1): André Martinet versteht unter 'doppelter Gliederung' die Unterteilung natürlicher Sprachen (a) in kleinste bedeutungsunterscheidende Einheiten (Phoneme) und (b) in kleinste bedeutungstragende Einheiten (Morpheme, wobei sich noch lexikalische und grammatische Morpheme voneinander unterscheiden lassen). Kleinste bedeutungstragende Einheiten sind gemäß de Saussures Zeichen mit Inhalt (concept) und Ausdruck (image); was die Ausdrucksseite angeht (image = Phonemketten, in Sonderfällen ein einziges Phonem), so ist die 'doppelte Gliederung' insofern sehr ökonomisch, als wir in allen natürlichen Sprachen der Welt aus einer Menge von zwischen 25 bis 35 Phonemen 10.000 und mehr Morpheme bilden können, und das ausschließlich durch je andere Kombination von Phonemen.
Wir haben im Rahmen der Diskussion der Ökonomie der 'doppelten Gliederung' eine Übertragung auf die Schriftsprache vorgenommen (zunächst ging es bei der 'doppelten Gliederung' um gesprochene Sprache). In Sprachen mit einem Alphabetschriftsystem (z.B. das Deutsche, dass - historisch gesehen - das lateinische Alphabet verwendet) entsprechen die Grapheme (die einzelnen Buchstaben) tendenziell den Phonemen; hier haben wir auch im Schriftlichen eine 'doppelte Gliederung'.
Es gibt aber auch ganz anders geartete Schriftsysteme, so die Bilderschriften, bei denen ein elementares Schriftzeichen tendenziell einem Morphem entspricht. In diesem Fall haben wir es also mit Schriftsprachen zu tun, die keine 'doppelte Gliederung' kennen, - so etwa die chinesische Bilderschrift. Und wieviele Schriftzeichen umfaßt eine solche Bilderschrift? Tendenziell so viele, wie eine solche Sprache Morpheme hat, also tendenziell 10.000 und mehr!
In der Grundschule wird eine Alphabetschrift (bzw. das Lesen und Schreiben) tendenziell in 1,5 bis 2 Jahren gelernt. Um eine Bilderschrift vollständig zu beherrschen, braucht man erheblich mehr (gegebenenfalls ein ganzes Leben), und das macht den Sinn bzw. die Ökonomie von Sprachen mit 'doppelter Gliederung' noch einmal sehr schön deutlich.
Zu (2): Ersichtlich setzt sich die Gesamtbedeutung von "zweihundert" nicht nur aus der Bedeutung (a) = "zwei" und (b) = "hundert" zusammen (denn da a + b = b + a ist, müßte dann ja auch "zwei-hundert" = "huntert-zwei" gelten). Offensichtlich kommt inhaltlich etwas hinzu (bei "zwei-hundert" die Multiplikation, bei "hundert-zwei" die Addition), was nicht segmental durch ein eigenes Phonem, sondern nur durch die je spezifische Anordnung oder Reihenfolge ausgedrückt wird (bei "zwei-hundert" die kleinere Zahl vor der Größeren, bei "hundert-zwei" die größere Zahl vor der kleineren).
Vergleichbar müssen wir auch in den folgenden Beispielen die Reihenfolge der Morpheme und Morphemsequenzen mitberücksichtigen, die zur Gesamtbedeutung einen spezifischen Beitrag leisten:
Klaus kommt - kommt Klaus
Bierfaß - Faßbier
Allgemein hatten wir festgehalten, dass wir bei der Zusammensetzung elementarer Morpheme Bauplänen folgen, die ihrerseits für die Gesamtbedeutung relevant sind, - so z.B. der Bauplan "Aussagesatz" in "Klaus kommt." im Unterschied zum Bauplan "Fragesatz" in "Kommt Klaus?" (dabei beide Äußerungen gesprochen-sprachlich gegebenenfalls mit derselben Tonhöhen- bzw. Intonationskontur).
Die hier angesprochenen Baupläne - es geht um syntagmatische Zusammenhänge, NICHT um paradigmatische Zusammenhänge - sind Gegenstand einer besonderen Teildisziplin der Sprachwissenschaft, der Syntax. Allerdings werden unterschiedliche Baupläne nicht nur durch unterschiedliche Reihenfolgen ausgedrückt; hier spielen von Fall zu Fall auch spezifische grammatische Morpheme eine Rolle, - von Fall zu Fall werden also Baupläne auch segmental ausgedrückt.
Zu (3): Woran erkennt man, welche Nominalgruppe in einem aktivischen Handlungssatz den 'Agenten' oder 'Täter' (= agens) wiedergibt und welche Nominalgruppe den Betroffenen wiedergibt? Man vergleiche
Hans hat Erna geohrfeigt.
Den Hans hat die Erna geohrfeigt.
Offensichtlich sind es die Kasusmorpheme (nämlich der Nominativ vs. der Akkusativ), die hier markieren, wer Täter und wer Opfer ist.
Woran erkennt man, welche Morpheme und Morphemsequenzen zusammengehören (ein- und dieselbe syntaktische Position belegen)? Auch das erkennt man über die Stellung solcher Morpheme und Morphemsequenzen hinaus u.a. am Kasus, - Teile einer Nominalgruppe wie der Artikel, ein attributives Adjektiv und das Nomen müssen im Kasus übereinstimmen (zusätzlich aber auch im Genus und im Numerus). Wir sprechen hier auch von morphologischer Kongruenz - vergleichbar muß die Subjektsnominalgruppe und das finite bzw. konjugierte Verb im Numerus und in der Person übereinstimmen.
Zusammengefaßt sind Kasusmorpheme ein Beispiel für die segmentale Markierung von Bauplänen bzw. ein Beispiel für syntaktische relevante grammatische Morpheme.
7.4. Probeklausur 4(1) Nennen und erläutern Sie die drei Testverfahren, die wir in der strukturell-deskriptiven Linguistik kennengelernt und bei der Satzanalyse angewandt haben.
(2) Geben Sie pro Testverfahren ein eigenes Beispiel, an dem Sie erläutern, wie jeweils ein Testverfahren funktioniert. (3) "Das Gebäude brannte lichterloh". - Geben Sie eine vollständige Valenzbeschreibung des standarddeutschen Verbs "brennen". Zu (1): Substitutionstest = Versuch, paradigmatisch auszutauschen bzw. zu überprüfen, ob es zu einem hypothetisch angenommenen Segment ein ganzes Paradigma hier ersatzweise einsetzbarer Ausdrücke und Ausdruckskomplexe gibt. Verlangt wird nur, dass dabei wieder ein grammatisch korrekter Satz entsteht. Permutationstest = syntagmatisch die Segmente umstellen (dabei bleibt die Bedeutung natürlich nicht gleich, - verlangt wird nur, dass wieder ein grammatisch korrekter Satz entsteht). - Der Permutationstest zeigt, welche Segmente stets zusammen auftreten, welche Segmente also eine eigene Gruppe bilden. Deletionstest = Überprüft wird, welche Ausschnitte in einer Äußerung ich weglassen kann, - allerdings muß auch dabei wieder ein grammtisch korrekter und auch grammatisch vollständiger Satz entstehen. Zu (2): Den Substitutionstest haben wir in zweierlei Verwendungen erlebt; einmal ging es darum kleinstmögliche bedeutungstragende Segmente zu finden. Zum anderen ging es darum, die größten Guppen innerhalb einer Äußerung bzw. innerhalb eines Satzes zu finden. Beispielsweise beweisen die folgenden paradigmatischen Austauschverhältnisse, dass eine konjugiertes Verb wie "(ich) lache" aus drei Segmenten besteht:
Vergleichbar belegen die folgenden paradigmatischen Austauschverhältnisse, dass der zugrundegelegte Satz zunächst einmal aus nur zwei 'größtmöglichen' Gruppierungen besteht:

Im Permutationstest ergeben sich die folgenden Umstellungsmöglichkeiten (agrammatische Umstellungen sind mit einem vorangestellten Sternchen gekennzeichnet):

Wende ich den Deletionstest an auf eine Äußerung bzw. einen Satz wie "Gestern hat sich meine alte Tante fürchterlich über Ihre kleinen Enkel aufgeregt", dann ergibt sich der 'Kernsatz' bzw. als 'Kernsatz' "Meine Tante hat sich aufgeregt" (und das ist ein Satz, der sich sehr viel leichter als der Ausgangssatz weiter analysieren läßt).
Zu (3): Lesarten = bei "brennen" gibt es mehrere Lesarten, die sich auch im Valenzrahmen bzw. in der Valenzbeschreibung unterscheiden. Neben "brennen" = 'Feuer' gibt es auch "Das brennt" im Sinne von 'das tut weh' - oder dann "Ich brenne darauf, es nochmals zu versuchen" im Sinne von 'ich möchte unbedingt' (dieses "brennen" hat auch einen anderen Valenzrahmen!). Wertigkeit von "brennen" in "Das Gebäude brannte lichterloh" = einwertig; dieser eine Aktant ist obendrein obligatorisch (muß also stets auftreten). - Konstruktionen wie "Es brannte lichterloh" stellen einen Sonderfall dar, - das "es" kann hier bewußt, gezielt ausblenden wollen, was denn da brannte. Es ist dennoch nicht mit dem "es" bei Witterungsverben vergleichbar. Morphologisch-grammatische Charakterisierung des ersten Aktanten (gezählt gemäß Abfolge im Beispiel): Nominalgruppe im Nominativ. Semantische Charakterisierung des einen Aktanten: Alles, was brennbar ist; Gegenständliches, stets 'konkret', nie 'abstrakt' (es sei denn im Rahmen metaphorischen Sprachgebrauchs), nie 'Sachverhalte'. 7.5. Probeklausur 5(1) Geben Sie eine Valenzbeschreibung des (konjugierten) Verbs in "Er glaubt, dass sie das schaffen".
(2) Erläutern Sie knapp, was in der modernen Sprachwissenschaft unter 'Diathese' verstanden wird. Geben Sie ein Beispiel.
(3) Was verstehen Sie unter den 'Genera des Verbs'? Was haben diese mit dem Subjekt zu tun? Welche Leistung, welchen 'Bedeutungsbeitrag' erbringen die 'Genera des Verbs', welche Leistung, welchen 'Bedeutungsbeitrag' erbringt das Subjekt (bzw. die 'Subjektivierung' eines Sachverhaltsausschnitts, eines Ausschnitts aus einer 'semantischen Szene')?
Zu (1): Lesarten = "glauben" hat mehrere Lesarten; hier liegt die Lesart 'vermuten, dass ...' vor. (= 2 Punkte)
Wertigkeit = In dieser Lesart ist das Verb "glauben" zweiwertig; beide Aktanten sind obligatorisch. (Nicht klar ist, inwieweit dennoch im Rahmen sog. eleptischen Sprechens der zweite Aktant ausgelassen werden kann - aber das ist ein Problem für sich!) (= 2 Punkte)
Morphologisch-grammatische Charakterisierung des ersten Aktanten (gezählt gemäß Abfolge im Beispiel): Nominalgruppe im Nominativ . Der zweite Aktant ist ein (eingeleiteter oder uneingeleiteter) Nebensatz - oder eine Pronominalform (= 2 Punkte)
Semantische Charakterisierung des ersten Aktanten: Nur Menschen können etwas glauben / vermuten (andere Verwendungen sind metaphorischer Natur). Der zweite Aktant ist ein Sachverhalt (und der 'Erstaktant' 'glaubt' bzw. vermutet das Bestehen oder nicht-Bestehen dieses Sachverhaltes). (= 2 Punkte)
Zu (2): Dynamisch gesehen wird unter 'Diathese' die Abbildung einer universellen rollensemantischen Struktur in / auf eine einzelsprachliche morphosyntaktische Struktur verstanden. Im Deutschen grammatisch festgelegte ('grammatikalisierte') unterschiedliche Formen der Abbildung bzw. unterschiedliche Realisierungen ein- und derselben rollensemantischen Struktur sind die 'Genera des Verbs'. Neben den 'grammatikalisierten' Möglichkeiten einer je unterschiedlichen diathetischen Abbildung gibt es weitere Möglichkeiten, so bestimmte Reflexivkonstruktionen wie "Das Buch liest sich gut" und modale Infinitive. (= 8 Punkte)
Zu (3): Mit 'Genera des Verbs' (genus verbi) sind Aktiv, werden-Passiv bzw. werden-Periphrase und die bekommen-Periphrase gemeint ("Sie bekommt von ihm Ohrringe geschenkt"). Dabei werden im Aktiv wie werden-Passiv wie (soweit möglich) in der bekommen-Periphrase je andere Ausschnitte zum Subjekt gemacht. Man könnte auch sagen, dass es unterschiedliche diathetische Abbildungen gibt, dass es die Genera des Verbs gibt, um einen je anderen Ausschnitt der zugrundeliegenden semantischen Szene zum Subjekt machen zu können.
Hintergrund ist die spezifische kognitive Leistung des Subjekts: Es markiert denjenigen Ausschnitt aus einer Szene, der für den Sprecher den höchsten Wert an 'kognitiver Hervorgehobenheit' hat (wir sprechen hier auch von salience und salience-Wert); was ist damit gemeint? Teilweise betrifft das das subjektive Betroffensein ("Mein Fahrrad ist weg"), teilweise sind es aber auch objektivierbare Prinzipien der Verarbeitung - so, dass alles, was oben ist, einen höheren salience-Wert hat als dasjenige, was unten ist (so bei der Beschreibung der räumlichen Verhältnisse der folgenden zwei Bildelemente 'Linie' und 'Stern' in einem einzigen Aussagesatz:
Hier macht der überwiegende Teil der Testpersonen den 'Stern' zum Subjekt, etwa in Sätzen wie "Über einer Linie befindet sich ein Stern". - Neben der 'oben-unten-Bewertung spielt hier zusätzlich noch die Einteilung in 'Gestalt' und 'Hintergrund' ein Rolle; wir geben in aller Regel der 'Gestalt' einen höheren salience-Wert (und das ist hier der Stern) als dem 'Hintergrund' (das ist hier der Strich bzw. die Linie).
Zusammengefaßt erlauben es also u.a. die 'Genera des Verbs', auszudrücken, welcher Ausschnitt einer Szene für den Sprecher den höchsten salience-Wert hat. Und das bedeutet auch, dass die zugrundeliegende Szene mit einer je anderen Perspektive dargestellt wird. Bei aktivischen Handlungssätzen, bei denen der agens zum Subjekt gemacht wurde, sprechen wir z.B. von einer 'agentiven' oder - gleichbedeutend - von einer 'aktivischen' oder von einer 'Täter-zugewandten Perspektive'. Umgekehrt sprechen wir beim werden-Passiv von einer 'Täter-abgewandten Perspektive'; eine solche 'passivische Perspektive' liegt allerdings auch etwa in Formulierungen wie "Mein Fahrrad ist weg" vor. (zusammen 12 Punkte)
7.6. Probeklausur 6Bearbeiten Sie die folgenden Aufgaben:
(1) Was verstehen wir unter den 'Genera des Verbs', - welche haben Sie im Kurs kennen gelernt? (2) Warum gibt es unterschiedliche Genera des Verbs? Was leisten Sie im Rahmen der sog. 'Diathese'? (3) Was ist das Besondere am Kasus "Nominativ", was ist das Besondere am Subjekt (in Opposition etwa zu den Objekten und den hier begegnenden Kasusformen)? (4) Wo spielt im Sprachproduktionsmodell von Levelt die rollensemantische Struktur eines Satzes eine Rolle? Zu (1): Gemeint sind Aktiv und (werden-)Passiv; hinzu kommt in den neueren Grammatiken gegebenenfalls die "bekommen"-Periphrase, wie sie vorliegt in "Sie bekam von Ihrem Chef einen Strauß Rosen geschenkt". - Die 'Genera des Verbs' sind grammatikalisierte Diathese-Möglichkeiten, grammatikalisierte Möglichkeiten der diathetischen Abbildung ein- und derselben rollensemantischen Struktur in verschiedene morpho-syntaktische Strukturen. Zu (2): Unterschiedliche 'Genera des Verbs' im besonderen wie unterschiedliche diathetische Abbildungsmöglichkeiten im allgemeinen realisieren unterschiedliche Gewichtungen und eine darauf aufbauende unterschiedliche 'Perspektive'. Beispielsweise bedeutet das Aktiv zumindest bei Handlungssätzen eine 'agentive Perspektive' (der Agent 'steht im Vordergrund'), wohingegen ein werden-Passiv eine 'Täter-abgewandte Perspektive' ausdrückt. - In Verkürzung dieser Zusammenhänge wird statt von einer 'Täter-abgewandten Perspektive' auch von einer 'passivischen' Perspektive gesprochen. Und eine solche 'passivische Perspektive' kann auch vorliegen, wenn kein werden-Passiv vorliegt, so bei "Das Buch liest sich gut" oder "Mein Fahrrad ist weg". Zu (3): Dass bei der Verbalisierung eines Sachverhaltes ein bestimmter Ausschnitt zum Subjekt gemacht wird, markiert, dass dieser Ausschnitt den höchsten 'salience-Wert' (die höchste 'kognitive Hervorgehobenheit') trägt; wenn man so will, so wird die zugrundeliegende Szene vom Satzglied mit dem höchsten salience-Wert aus 'perspektiviert'. Beispielsweise ist in Handlungssätzen im Aktiv der Agent, der Handelnde, das Subjekt; d.h. dass der Agent den höchsten 'salience-Wert' trägt, dass wir eine 'agentive Perspektive', eine 'Täter-zugewandte Perspektive' realisieren, das z.B. in Opposition zu einer 'passivischen Perspektive', zu einer 'Täter-abgewandten Perspektive', wie sie das werden-Passiv realisiert, bei dem das 'semantische Objekt' zum Subjekt des Satzes gemacht wurde (agens, patiens, semantisches Objekt usw. sind rollensemantische Beschreibungen).Wollte man mit alltäglichen Begriffen ausdrücken, was mit 'salience' gemeint ist, dann vielleicht so: Derjenige Ausschnitt aus einer Szene, dem ich den höchsten 'salience-Wert' zuspreche, dieser Ausschnitt ist mir emotional und/oder intellektuell 'am nächsten'. Wenn ich beispielsweise aus der Uni komme und mein Fahrrad nicht mehr an der Laterne angeschlossen vorfinde, dann werde ich so gut wie immer Ausrufe produzieren wie "Mein Fahrrad ist weg" (Subjekt = höchster 'salience-Wert' = "mein Fahrrad"), weil mir in diesem Moment zunächst einmal egal ist, dass JEMAND mein Fahrrad (womöglich) gestohlen hat; viel wichtiger ist mir mein FAHRRAD, weil ich nun z.B. nicht mit dem Fahrrad nach Hause fahren kann.
Prozessual gesehen sprechen wir auch von der 'Subjektivierung' eines solchen Ausschnitts; ein bestimmter Ausschnitt wird in der morpho-syntaktischen Struktur zum Subjekt gemacht. - 'Die Subjektivierung' (und die Zuordnung des jeweils höchsten 'salience-Wertes') hat nichts zu tun mit der Thema-Rhema-Struktur (hier im Sinne des sog. Prager Strukturalismus, zu dem auch Trubetzkoy - siehe ganz zu Anfang dieses Teils - gehörte) bzw. prozessual mit der 'Thematisierung' eines Ausschnitts aus einer zugrundeliegende Szene zu tun. Und weder die 'Subjektivierung' noch die 'Thematisierung' hat mit der über Stellung oder / und Intonation realisierten kommunikativen Hervorhebung zu tun, wie sie am deutlichsten bei kontrastiver Betonung in Erscheinung tritt, - vgl. "Er hat das Fahrrad nicht VERSCHENKT, sondern GESTOHLEN". Zu (4): Die (universelle, d.h. außereinzelsprachliche) semantische Rollenstruktur ist bei Levelt der output der Planungsprozesse bzw. der konzeptuellen Vorbereitung ("conceptualizer") - und zugleich der input in die Formulierungsprozesse ("formulator"), genauer: der input in die grammatische Enkodierung ("grammatical encoding"):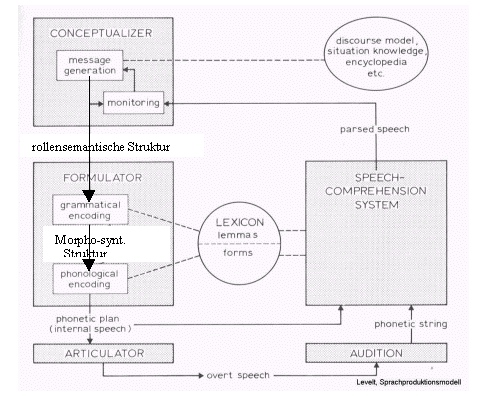
7.7. Probeklausur 7
(1) Skizzieren Sie wesentliche Leistungen der 'phonetischen' oder 'phonologischen Enkodierung' bei Levelt.
(2) Woher weiß die 'phonetische' oder 'phonologische Enkodierung' nach Levelt, wo sie im Wortformen-Lexikon jeweils gesuchte Wortformen findet?
(3) Ergebniss der Überarbeitung der im Wortformen-Lexikon gespeicherten Phonemfolgen ist ein phonetisches Programm, das die Artikulationsorgane steuert. Was entspricht diesem phonetische Programm, wenn wir neurolinguistische Begriffe verwenden?
Zu (1): Im Rahmen der phonetischen Enkodierung einer einzelsprachlichen (morpho-)syntaktischen Struktur geht es zunächst einmal darum, in Ersatz der Lemma's dazu gehörende Wortformen aus dem Wortformen-Lexikon aufzurufen und in die (morpho-)syntaktische Struktur einzusetzen. Hierbei handelt es sich um einen ziemlich komplexen Prozess, auf dessen Details wir im Kurs nicht näher eingegangen sind.
Phonemfolgen - so wie sie im Wortformen-Lexikon stehen - müssen aber gegebenenfalls noch für eine normgerechte Aussprache überarbeitet werden. Beispielsweise setzen wir vor vokalisch anlautende Segmente - z.B. die Konjunktion "und" - stets einen Glottisverschluß. Allgemeiner wird im Standarddeutschen jeder vokalisch 'offene' Beginn durch einen Glottisverschluß 'gedeckt', - wir sprechen auch von der standarddeutschen Glottalisierung; man vgl. auch etwa "ich", "auch", "aber" usw.usw.usw..
Gleichartig 'verhärten' wir im Standarddeutschen im 'ungedeckten' oder 'offenen Auslaut' jeden lenis-Frikativ und lenis-Verschluß. Entsprechend

Wir sprechen hier auch von der Auslautverhärtung des Standarddeutschen.
Schließlich ist ein prototypisches Beispiel für solche 'Überarbeitungsprozesse' die Koartikulation, wie sie z.B. bei der Artikulation "Glück" vorliegt: Hier bilden wir schon bei der Artikulation des anlautenden Verschlusses mit den Lippen ein zusätzliches Ansatzrohr, obwohl diese artikulatorische Teilbewegung Teil erst des "Ü" ist. Und wir rollen mehr oder weniger zur gleichen Zeit auch schon die Zunge nach oben ein, obwohl das eigentlich ein Teil der komplexen Artikulation des "L" ist.
Zu (2): Levelt hat (jedenfalls zunächst) die Arbeitsweise seines Sprachproduktionsmodells in Anlehnung an die Arbeitsweise eines Computers gedacht. Entsprechend ist das Lexikon - hier das 'Ausdruckslexikon' bzw. Wortformen-Lexikon - ein Speicher mit adressierten Plätzen, auf denen - hier: Wortformen lagern. Aber bereits Teil eines Lemma's (das ist ein Eintrag im 'Inhaltslexikon') ist eine Adresse für das Wortformen-Lexikon, und aufgrund dieser Adresse 'weiß' die phonetische oder phonologische Enkodierung, wo sie die zu einem Lemma passende Wortform suchen muß.
Zu (3): Dem phonetischen Programm als Output der phonetischen oder phonologischen Enkodierung entspricht neurolinguistisch am ehesten ein in sekundär-motorischen Regionen abgespeichertes komplexes motorisches Programm (Broca-Region), dass die primär-motorische Region steuert und via primär-motorische Region spezifische Muskeln der artikulatorischen Motorik aktiviert. - Im Unterschied zu den in Anlehnung an Levelt oben entwickelten Vorstellungen geht die Neurolinguistik allerdings davon aus, das streng genommen nicht immer wieder erneut ein solches komplexes motorisches Programm erzeugt werden muß, sondern dass solche motorischen Programme bereits ganzheitlich gespeichert zur Verfügung stehen.
8. Lexikalische SemantikSiehe hierzu den Teil IV, der in Kürze verfügbar sein wird.
